Why Deep Learning in AI and what is ImageNet yearly challenge?
It is Olympics of computer vision!, Every year, researchers attempt to classify images into one of 200 possible classes given a training dataset of approximately 450,000 images.
The goal of the competition is to push the state of the art in computer vision to rival the accuracy of human vision itself (approximately 95– 96%).
In 2012, Alex Krizhevsky at the University of Toronto did the unthinkable. Pioneering a deep learning architecture known as a convolutional neural network for the first time on a challenge of this size and complexity, he blew the competition out of the water. The runner up in the
competition scored a commendable 26.1% error rate. But AlexNet, over the course of just a few months of work, completely crushed 50 years of traditional computer vision research with an error rate of approximately 16%
What is the Deep Learning Tools?
PyTorch is a machine learning and deep learning tool developed by Facebook’s artificial intelligence division to process large-scale image analysis, including object detection, segmentation and classification.
the other available tools are TensorFlow (developed by google), Theano (by University of Montreal), Caffe, Neon, and Keras.
TensorFlow vs PyTorch Concept-wise there are certain differences:
• In TensorFlow, we have to define the tensors, initialize the session, and keep placeholders for the tensor objects; however, we do not have to do these operations in PyTorch.
• In TensorFlow, let’s consider sentiment analysis as an example. Input sentences are tagged with positive or negative tags. If the input sentence’s length is not equal, then we set the maximum sentence length and add zero to make the length of other sentences equal, so that the recurrent neural network can function; however, this is a built-in functionality in PyTorch, so we do not have to define the length of the sentences.
• In PyTorch, the debugging is much easier and simpler, but it is a difficult task in TensorFlow.
How to install PyTorch
it will show all output labels and how confident we are in our predictions. the output depends on the outputs of all the other neurons.
So, if the input image ask if the content is dog or cat,
softmax layers at the end may answer with 0.9 cat, 0.1 dog
Gradient Descent
In neural network, how exactly do we figure out the weights for each node in neural network?
This is accomplished by training
t(i) is the true answer for the (i)th training example
y(i) is the value computed by the neural network,
we want to minimize the value of the error function E


E is zero when our model makes a perfectly correct prediction on every training example. Moreover, the closer E is to 0, the better our model is.
As a result, our goal will be to select our parameter vector θ (the values for all the weights in our model) such that E is as close to 0 as possible.
use gradient descent algorithm to minimize the squared error over all of the training examples.
But gradient descent algorithm may not solve the problem if we have many local minimum
 Should Local minima solved and find true global minimum?
Should Local minima solved and find true global minimum?
No, in most cases, no need to overcome Local minimum problem!
However, in case your network is stuck in a bad local minimum then you need to tune your hyper parameters. You could try some of the following methods:
Difference between back-propagation and feed-forward Neural Network?
- Feed forward is algorithm to calculate output vector from input vector.
- Back propagation is algorithm to train (adjust weight) of neural network.
When you are training neural network, you need to use both algorithms.
When you are using neural network (which have been trained), you are using only feed-forward.
Feed Forward Neural Networks
use back-propagation during training time only
In these types of neural networks information flows in only one direction i.e. from input layer to output layer.
When the weights are once decided, they are not usually changed.
The nodes here do their job without being aware whether results produced are accurate or not(i.e. they don't re-adjust according to result produced).
There is no communication back from the layers ahead.
Feed Forward Limitations:
- Can't handle sequential data
- Considers only the current input
- Can't memorize previous inputs
Recurrent Neural Networks (Back-Propagating)
use back-propagation during training time and production use also
Information passes from input layer to output layer to produce result. Error in result is then communicated back to previous layers now.
Nodes get to know how much they contributed in the answer being wrong. Weights are re-adjusted. Neural network is improved. It learns.
There is bi-directional flow of information. This basically has both algorithms implemented, feed-forward and back-propagation.
Popular Neural Networks are:

Multilayer Perceptrons (MLPs)
it is a classical type of neural network. They are comprised of one or more layers of neurons. Data is fed to the input layer, there may be one or more hidden layers providing levels of abstraction, and predictions are made on the output layer, also called the visible layer.
They are very flexible and can be used generally to learn a mapping from inputs to outputs.
This flexibility allows them to be applied to other types of data. For example, the pixels of an image can be reduced down to one long row of data and fed into a MLP. The words of a document can also be reduced to one long row of data and fed to a MLP. Even the lag observations for a time series prediction problem can be reduced to a long row of data and fed to a MLP.

Use MLPs For:
RNN
RNN is a neural network with memory (It can memorize previous inputs to help in predict the next)
But we may face gradient problem (Vanishing or Exploding)




CNN (Convolutional Neural Networks, also called ConvNet)
CNN were developed for object recognition tasks such as handwritten digit recognition.
CNN vs RNN
CNN is a feed forward neural network that is generally used for Image recognition and object classification.
While RNN works on the principle of saving the output of a layer and feeding this back to the input in order to predict the output of the layer.
CNN considers only the current input
while RNN considers the current input and also the previously received inputs. It can memorize previous inputs due to its internal memory.
RNN can handle sequential data while CNN cannot.
In RNN, the previous states is fed as input to the current state of the network. RNN can be used in NLP, Time Series Prediction, Machine Translation, etc.
CNN has 4 layers namely: Convolution layer, ReLU layer, Pooling and Fully Connected Layer. Every layer has its own functionality and performs feature extractions and finds out hidden patterns.
There are 4 types of RNN namely: One to One, One to Many, Many to One and Many to Many.
(because RNNs has designed to work with sequence prediction problems)
- One-to-One: known as Vanilla NN, An observation as input mapped to one output
- One-to-Many: An observation as input mapped to a sequence with multiple steps as an output. for example an image can convert to dog catch a ball
- Many-to-One: A sequence of multiple steps as input mapped to class or quantity prediction. for example in sentimental analysis many works feed to classify it as positive or negative
- Many-to-Many: A sequence of multiple steps as input mapped to a sequence with multiple steps as output. for example machine translation, many words in input mapped to many words in output
The Long Short-Term Memory (LSTM) network is perhaps the most successful RNN because it overcomes the problems of training a recurrent network and in turn has been used on a wide range of applications.
Use CNNs For:
Use RNNs For:
Don’t Use RNNs For:
for more information about RNN
https://www.youtube.com/watch?v=lWkFhVq9-nc
for more information about CNN
https://www.youtube.com/watch?v=Jy9-aGMB_TE
It is Olympics of computer vision!, Every year, researchers attempt to classify images into one of 200 possible classes given a training dataset of approximately 450,000 images.
The goal of the competition is to push the state of the art in computer vision to rival the accuracy of human vision itself (approximately 95– 96%).
In 2012, Alex Krizhevsky at the University of Toronto did the unthinkable. Pioneering a deep learning architecture known as a convolutional neural network for the first time on a challenge of this size and complexity, he blew the competition out of the water. The runner up in the
competition scored a commendable 26.1% error rate. But AlexNet, over the course of just a few months of work, completely crushed 50 years of traditional computer vision research with an error rate of approximately 16%
What is the Deep Learning Tools?
PyTorch is a machine learning and deep learning tool developed by Facebook’s artificial intelligence division to process large-scale image analysis, including object detection, segmentation and classification.
the other available tools are TensorFlow (developed by google), Theano (by University of Montreal), Caffe, Neon, and Keras.
• In TensorFlow, we have to define the tensors, initialize the session, and keep placeholders for the tensor objects; however, we do not have to do these operations in PyTorch.
• In TensorFlow, let’s consider sentiment analysis as an example. Input sentences are tagged with positive or negative tags. If the input sentence’s length is not equal, then we set the maximum sentence length and add zero to make the length of other sentences equal, so that the recurrent neural network can function; however, this is a built-in functionality in PyTorch, so we do not have to define the length of the sentences.
• In PyTorch, the debugging is much easier and simpler, but it is a difficult task in TensorFlow.
How to install PyTorch
pip3 install torch torchvision
Deep Learning core concepts
Neural General Function

Let’s reformulate the inputs as a vector x = [x1 x2 ... xn] and the weights of the neuron as w = [w1 w2 ... wn].
Then we can re-express the output of the neuron as
y=f(x*w + b) , where b is the bias term.
In order to learn complex relationships, we need to use neurons that employ some sort of nonlinearity. There are three major types of neurons (Activation function) that are used in practice that introduce nonlinearities in their computations (Sigmoid, Tanh, and ReLU Neurons).
Activation function (or non-linearity)
1) Sigmoid neurons: S-shaped nonlinearity, takes a real-valued input and the output range from 0 to 1

Softmax Output LayersNeural General Function

Let’s reformulate the inputs as a vector x = [x1 x2 ... xn] and the weights of the neuron as w = [w1 w2 ... wn].
Then we can re-express the output of the neuron as
y=f(x*w + b) , where b is the bias term.
In order to learn complex relationships, we need to use neurons that employ some sort of nonlinearity. There are three major types of neurons (Activation function) that are used in practice that introduce nonlinearities in their computations (Sigmoid, Tanh, and ReLU Neurons).
Activation function (or non-linearity)
1) Sigmoid neurons: S-shaped nonlinearity, takes a real-valued input and the output range from 0 to 1
σ(x) = 1 / (1 + exp(−x))
tanh(x) = 2σ(2x) − 1
3) ReLU (Rectified Linear Unit), It takes a real-valued input and thresholds it at zero (replaces negative values with zero)
f(x) = max(0, x)

it will show all output labels and how confident we are in our predictions. the output depends on the outputs of all the other neurons.
So, if the input image ask if the content is dog or cat,
softmax layers at the end may answer with 0.9 cat, 0.1 dog
Gradient Descent
In neural network, how exactly do we figure out the weights for each node in neural network?
This is accomplished by training
y(i) is the value computed by the neural network,
we want to minimize the value of the error function E

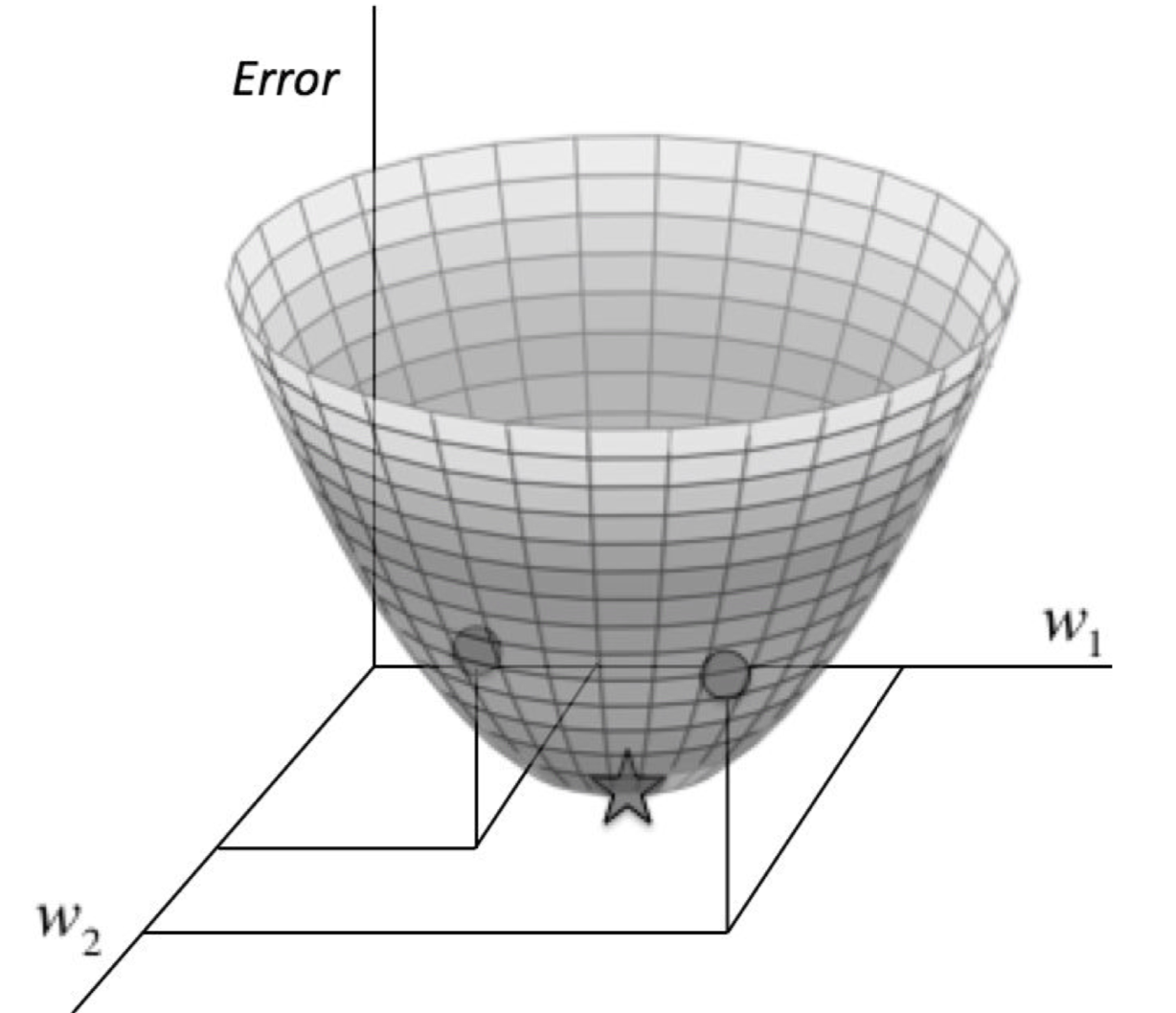
As a result, our goal will be to select our parameter vector θ (the values for all the weights in our model) such that E is as close to 0 as possible.
use gradient descent algorithm to minimize the squared error over all of the training examples.
But gradient descent algorithm may not solve the problem if we have many local minimum

No, in most cases, no need to overcome Local minimum problem!
However, in case your network is stuck in a bad local minimum then you need to tune your hyper parameters. You could try some of the following methods:
1) Increasing the learning rate: If the learning rate of your algorithm is too small then it is more likely to be stuck in a local minima.
2) Increasing hidden layers/units: It may help approximate the function better.
3) Trying different activation functions: Make sure that the combination of activation functions is apt for your model and dataset.
4) Trying different optimization algorithms: Instead of the conventional gradient descent, try using algorithms like Adam’s optimizer and RMSProp, Adagrad, Adadelta, RMSprop, and SGD
Difference between back-propagation and feed-forward Neural Network?
- Feed forward is algorithm to calculate output vector from input vector.
- Back propagation is algorithm to train (adjust weight) of neural network.
When you are training neural network, you need to use both algorithms.
When you are using neural network (which have been trained), you are using only feed-forward.
Feed Forward Neural Networks
use back-propagation during training time only
In these types of neural networks information flows in only one direction i.e. from input layer to output layer.
When the weights are once decided, they are not usually changed.
The nodes here do their job without being aware whether results produced are accurate or not(i.e. they don't re-adjust according to result produced).
There is no communication back from the layers ahead.
Feed Forward Limitations:
- Can't handle sequential data
- Considers only the current input
- Can't memorize previous inputs
Recurrent Neural Networks (Back-Propagating)
use back-propagation during training time and production use also
Information passes from input layer to output layer to produce result. Error in result is then communicated back to previous layers now.
Nodes get to know how much they contributed in the answer being wrong. Weights are re-adjusted. Neural network is improved. It learns.
There is bi-directional flow of information. This basically has both algorithms implemented, feed-forward and back-propagation.
Popular Neural Networks are:

- Multilayer Perceptrons (MLPs)
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
Multilayer Perceptrons (MLPs)
it is a classical type of neural network. They are comprised of one or more layers of neurons. Data is fed to the input layer, there may be one or more hidden layers providing levels of abstraction, and predictions are made on the output layer, also called the visible layer.
They are very flexible and can be used generally to learn a mapping from inputs to outputs.
This flexibility allows them to be applied to other types of data. For example, the pixels of an image can be reduced down to one long row of data and fed into a MLP. The words of a document can also be reduced to one long row of data and fed to a MLP. Even the lag observations for a time series prediction problem can be reduced to a long row of data and fed to a MLP.
Use MLPs For:
- Tabular datasets
- Classification prediction problems
- Regression prediction problems
for example, a dataset of gray scale images with the standardized size of 32×32 pixels each, a traditional feedforward neural network would require 1024 input weights (plus one bias).
This is fair enough, but the flattening of the image matrix of pixels to a long vector of pixel values loses all of the spatial structure in the image. Unless all of the images are perfectly resized, the neural network will have great difficulty with the problem.
RNN
RNN is a neural network with memory (It can memorize previous inputs to help in predict the next)
But we may face gradient problem (Vanishing or Exploding)




CNN (Convolutional Neural Networks, also called ConvNet)
CNN were developed for object recognition tasks such as handwritten digit recognition.
layers in a Convolutional Neural Network:
- Convolutional Layers.
- Pooling Layers.
- Fully-Connected Layers.
CNN is a feed forward neural network that is generally used for Image recognition and object classification.
While RNN works on the principle of saving the output of a layer and feeding this back to the input in order to predict the output of the layer.
CNN considers only the current input
while RNN considers the current input and also the previously received inputs. It can memorize previous inputs due to its internal memory.
RNN can handle sequential data while CNN cannot.
In RNN, the previous states is fed as input to the current state of the network. RNN can be used in NLP, Time Series Prediction, Machine Translation, etc.
CNN has 4 layers namely: Convolution layer, ReLU layer, Pooling and Fully Connected Layer. Every layer has its own functionality and performs feature extractions and finds out hidden patterns.
There are 4 types of RNN namely: One to One, One to Many, Many to One and Many to Many.
(because RNNs has designed to work with sequence prediction problems)
- One-to-One: known as Vanilla NN, An observation as input mapped to one output
- One-to-Many: An observation as input mapped to a sequence with multiple steps as an output. for example an image can convert to dog catch a ball
- Many-to-One: A sequence of multiple steps as input mapped to class or quantity prediction. for example in sentimental analysis many works feed to classify it as positive or negative
- Many-to-Many: A sequence of multiple steps as input mapped to a sequence with multiple steps as output. for example machine translation, many words in input mapped to many words in output
The Long Short-Term Memory (LSTM) network is perhaps the most successful RNN because it overcomes the problems of training a recurrent network and in turn has been used on a wide range of applications.
Below is an example of how CNN looks like:
A Recurrent Neural Network looks something like this:
Use CNNs For:
- Image data
- Classification prediction problems (document classification / sentiment analysis )
- Regression prediction problems
- Text data
- Time series data
- Sequence input data
Use RNNs For:
- Text data
- Speech data
- Classification prediction problems
- Regression prediction problems
- Generative models
Don’t Use RNNs For:
- Tabular data
- Image data
for more information about RNN
https://www.youtube.com/watch?v=lWkFhVq9-nc
for more information about CNN
https://www.youtube.com/watch?v=Jy9-aGMB_TE